
Le machine learning ou ML est une branche de l’intelligence artificielle. C’est un programme informatique qui apprend de données pour accomplir une tâche. En français, on pourrait dire « apprentissage automatique ». Le Machine Learning désigne bien le concept selon lequel un algorithme peut apprendre à partir de données récoltées, puis prendre des décisions stratégiques suite à leur analyse et leur modélisation.
Malgré ses débuts en 1950, avec le célèbre Alan Turing, il aura fallu attendre les années 2010 pour que l’intelligence artificielle explose. Notamment grâce à l’évolution de la puissance de calcul des ordinateurs, aux nouvelles méthodes d’apprentissage automatique et au big data. Comme toute innovation, l’objectif final est bien d’apporter un progrès dans nos existences. Pourtant, le machine learning, destiné à améliorer nos existences est accusé de discriminations…
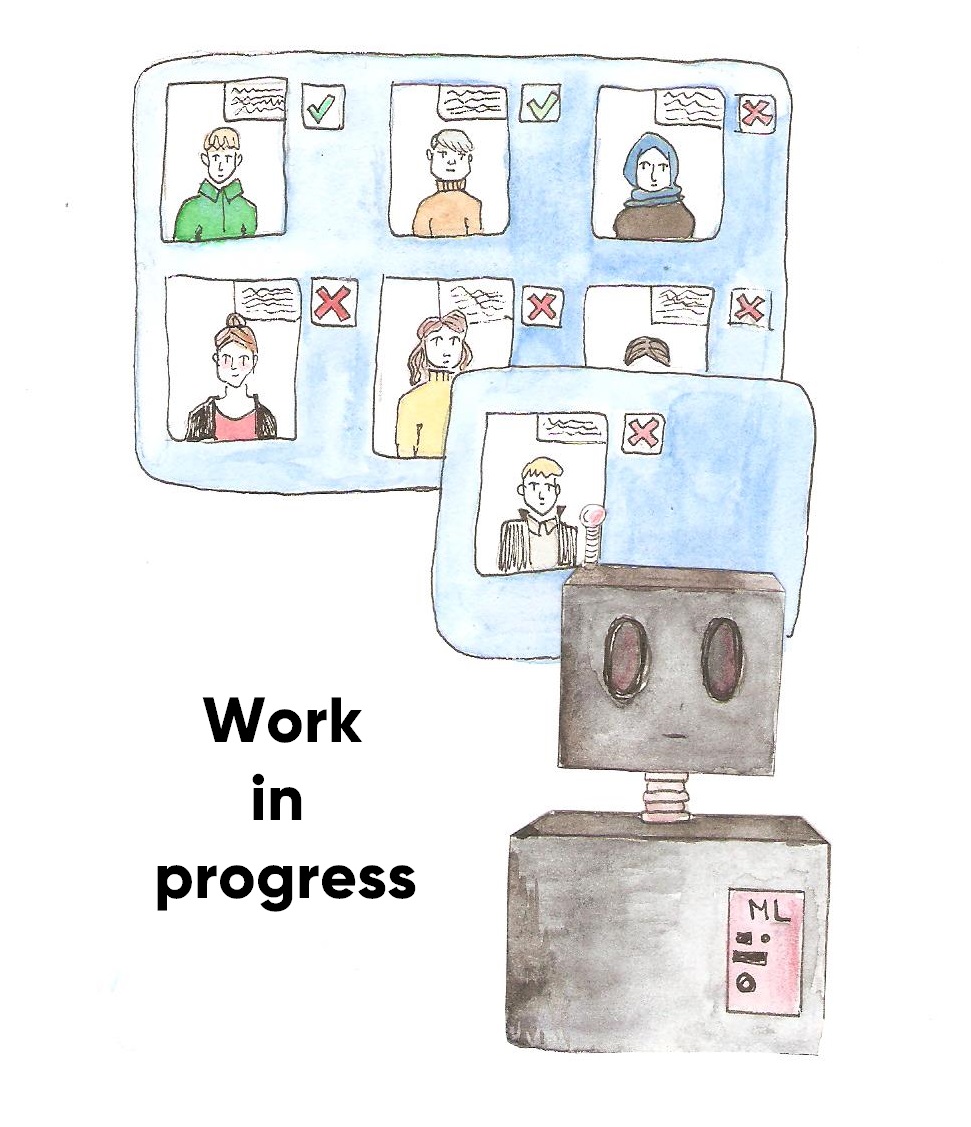
Aujourd’hui, les secteurs public et privé s’appuient sur le machine learning pour prendre des décisions. Cependant ces algorithmes peuvent parfois être biaisés ce qui pose problème au vu des choix qu’ils influencent : recrutement, accord de prêt, prix différenciés, justice prédictive… Par exemple l’algorithme de recrutement d’Amazon qui desservait les femmes pour les postes techniques ou liés à l’informatique. Ou encore COMPAS, logiciel utilisé par la justice américaine pour estimer les risques de récidive, qui évalue comme à « haut risque » 2 fois plus souvent les personnes noires que blanches, sans pour autant qu’elles récidivent.
 Se pose alors la question suivante : pourquoi un logiciel de ML en arrive à faire de la discrimination ? Pour comprendre, il faut se pencher sur le fonctionnement du machine learning. Ce type d’algorithmes s’appuie sur une base de données, avec des exemples X et, pour chacun de ces exemples, une cible Y (apprentissage supervisé). Prenons le logiciel de recrutement d’Amazon : celui-ci dispose des CVs des anciens postulants (=X), et des réponses de la DRH (Direction des ressources Humaines, le service qui embauche). Des personnes qui ont été soit recrutées ou refusées (=Y). Puis en explorant les données et par la magie des mathématiques, le logiciel apprend et arrive avec un certain pourcentage de réussite à déterminer si tel CV est recruté ou non. On peut après cet apprentissage lui soumettre un nouveau profil et s’appuyer sur sa réponse pour prendre la décision. Si l’algorithme s’avère discriminant (et que ce n’est pas voulu), ce sont les données qui sont le plus souvent mises en cause.
Se pose alors la question suivante : pourquoi un logiciel de ML en arrive à faire de la discrimination ? Pour comprendre, il faut se pencher sur le fonctionnement du machine learning. Ce type d’algorithmes s’appuie sur une base de données, avec des exemples X et, pour chacun de ces exemples, une cible Y (apprentissage supervisé). Prenons le logiciel de recrutement d’Amazon : celui-ci dispose des CVs des anciens postulants (=X), et des réponses de la DRH (Direction des ressources Humaines, le service qui embauche). Des personnes qui ont été soit recrutées ou refusées (=Y). Puis en explorant les données et par la magie des mathématiques, le logiciel apprend et arrive avec un certain pourcentage de réussite à déterminer si tel CV est recruté ou non. On peut après cet apprentissage lui soumettre un nouveau profil et s’appuyer sur sa réponse pour prendre la décision. Si l’algorithme s’avère discriminant (et que ce n’est pas voulu), ce sont les données qui sont le plus souvent mises en cause.
Par exemple, si dans les données, 90% des recrutés sont des hommes, l’algorithme va probablement déduire qu’il vaut mieux un homme. Il reproduira donc le comportement de la DRH, et si celui-ci était déjà biaisé, l’algorithme le sera aussi.
Pour se prémunir des algorithmes biaisés, les organisations utilisant le machine learning doivent former et prévenir le personnel sur les risques de discrimination. Différentes mesures doivent être prises lors de la mise en oeuvre d’un projet de machine learning :
l’association de spécialistes de différents domaines, l’évaluation des risques de discrimination, la surveillance du déploiement de l’algorithme… Des cas de discriminations ont été repérés et dénoncés aux USA tout récemment, en novembre chez Apple par exemple (avec l’Apple Card).
On peut penser qu ‘un algorithme n’est pas écrit directement pour discriminer telle ou telle population, mais les intelligences artificielles, nourries par des années d’historique de données, ont tendance à reproduire les discriminations déjà présentes dans la société.
Les exemples se multiplient à l’étranger. La France semble épargnée mais pour combien de temps ?… Le machine learning et plus généralement l’intelligence artificielle présente donc aujourd’hui des risques de discriminations. C’est aux entreprises et aux humains qui les dirige de reprendre la main car cet outil promet, s’il est bien utilisé, de vraies opportunités pour la société.
Gildas (illustration d’Andréane)